Idempotency
Retries can create problems, see how systems prevent it.
Tiny Summary
Retries and crashes are unavoidable. Idempotency is how systems survive them.
What is Idempotency & Why It'll Save You from Pain
Distributed systems (software systems that communicate over the network), have failures from time to time.
Some issues that happen in distributed systems:
- Networks fail
- Timeouts happen
- Servers crash
- Responses get lost
Just like in everyday life when things fail, the first thing we do is Retry.
Daily Examples of Retries:
- Starting a car: Turn key, doesn't work → you retry
- Sending a text: "Not delivered" → resend
- Refreshing a browser: Page didn’t load → refresh
Retrying is typically the simplest thing to do, and it usually fixes the problem.
But... there are types of things that are safe to retry and some that are not.
✅ Things that ARE safe to retry:
- Checking your bank balance
- Looking up an order status
- Checking the weather
❌ Things that are NOT safe to retry:
- Charging a credit card
- Sending an email
- Booking a flight or hotel
Idempotency (doing something once has the same effect as doing it many times) becomes a must when we retry things that are NOT safe to retry.
The key is to implement systems that produce "side effects" (things not safe for retries) in an idempotent way. So that, when failures come, and retries inevitably happen, no harmful side effects occur.
Quick gut-check
Ask yourself: "If this runs twice by accident, am I okay?"
- ✅ Yes → probably idempotent
- ❌ No → not idempotent
Two Types of Flows where Idempotency is Necessary
1. Inbound (Consumer idempotency)
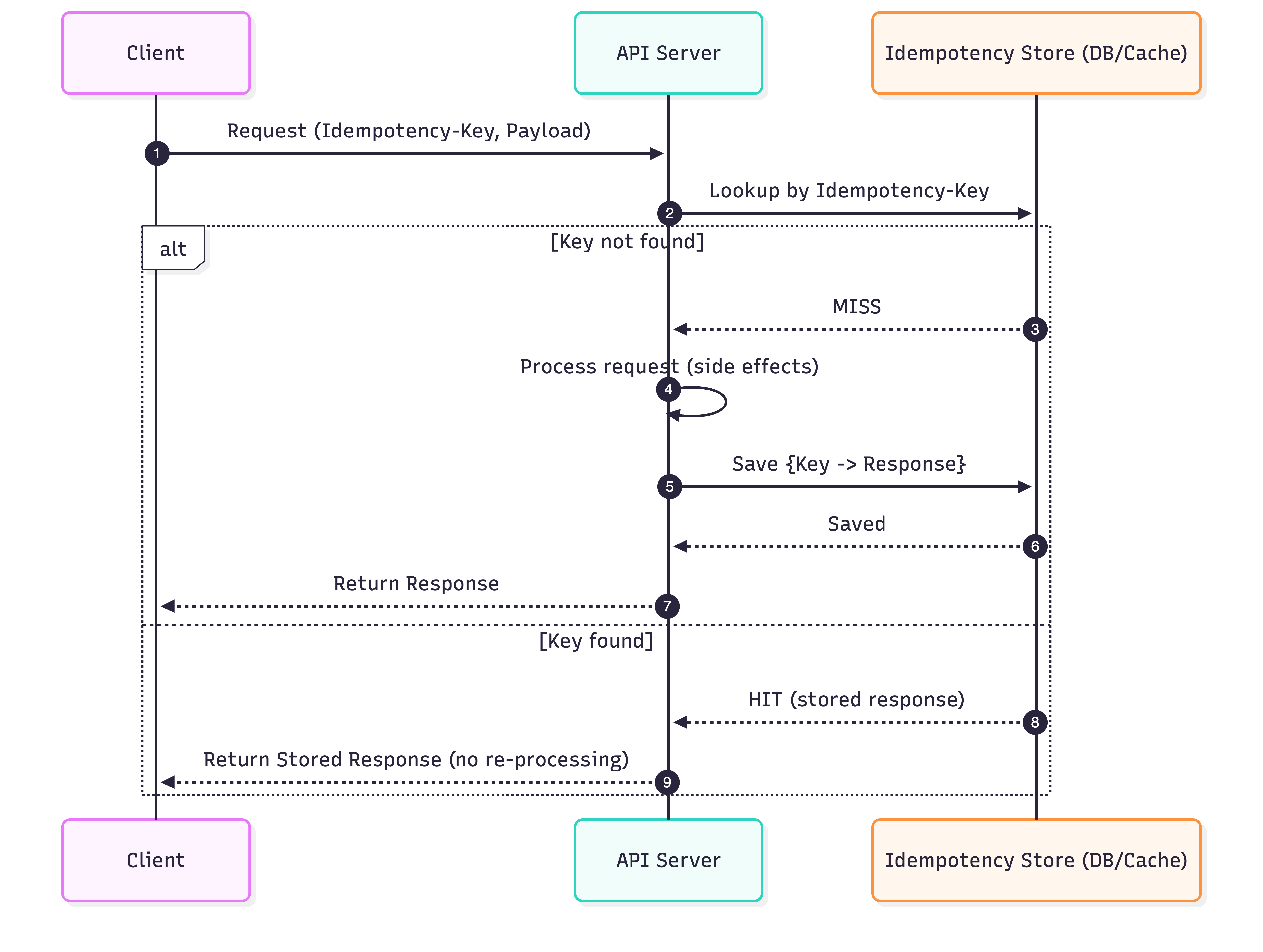
Let's say you work at an airline company, you are tasked with building an API for booking flights. Your API will get "inbound" requests from various clients wanting to book flights.
Because we know distributed systems are unreliable at times, we should design our API to be idempotent. We want to prevent any duplicate requests we get from booking multiple flights.
How do we implement this? The basic idea is for each request we receive, we need to check if we've already processed the same request previously or not (using some unique identifier, a unique request specific idempotency-key is best). That way, if we have see the request before, we can just return the previous response. That way there are no bad side effects that happen.
Idempotency-Key = key that uniquely identifies the request message
See below diagram for the flow:
2. Outbound (Producer idempotency)
Now let's say we're on the other side now, and you're building a service that needs to send payment requests to a third-party payment processor. Your service will make "outbound" requests to the payment processor API.
Because networks can fail and responses can be lost, you might configure your service to retry the payment request if it fails. But, (very importantly) you only want to charge the customer once even if your system retries.
How do we implement this? Similar to the inbound flow, you'll need to generate (and include) a unique idempotency-key in each payment processor API request. This idempotency-key will need to be included as part of any retries that you do as well. The receiving API will use this key to detect duplicates and ensure the operation only happens once. (Just like we did in the inbound flow above)
Key differences from Inbound:
- YOU generate the idempotency key (not the client)
- YOU must persist the key before making the request
- YOU must use the same key on retries
- The DOWNSTREAM service enforces idempotency
This ensures that even if your service crashes and restarts, or retries multiple times, the downstream operation only happens once.
See below diagram for the flow: